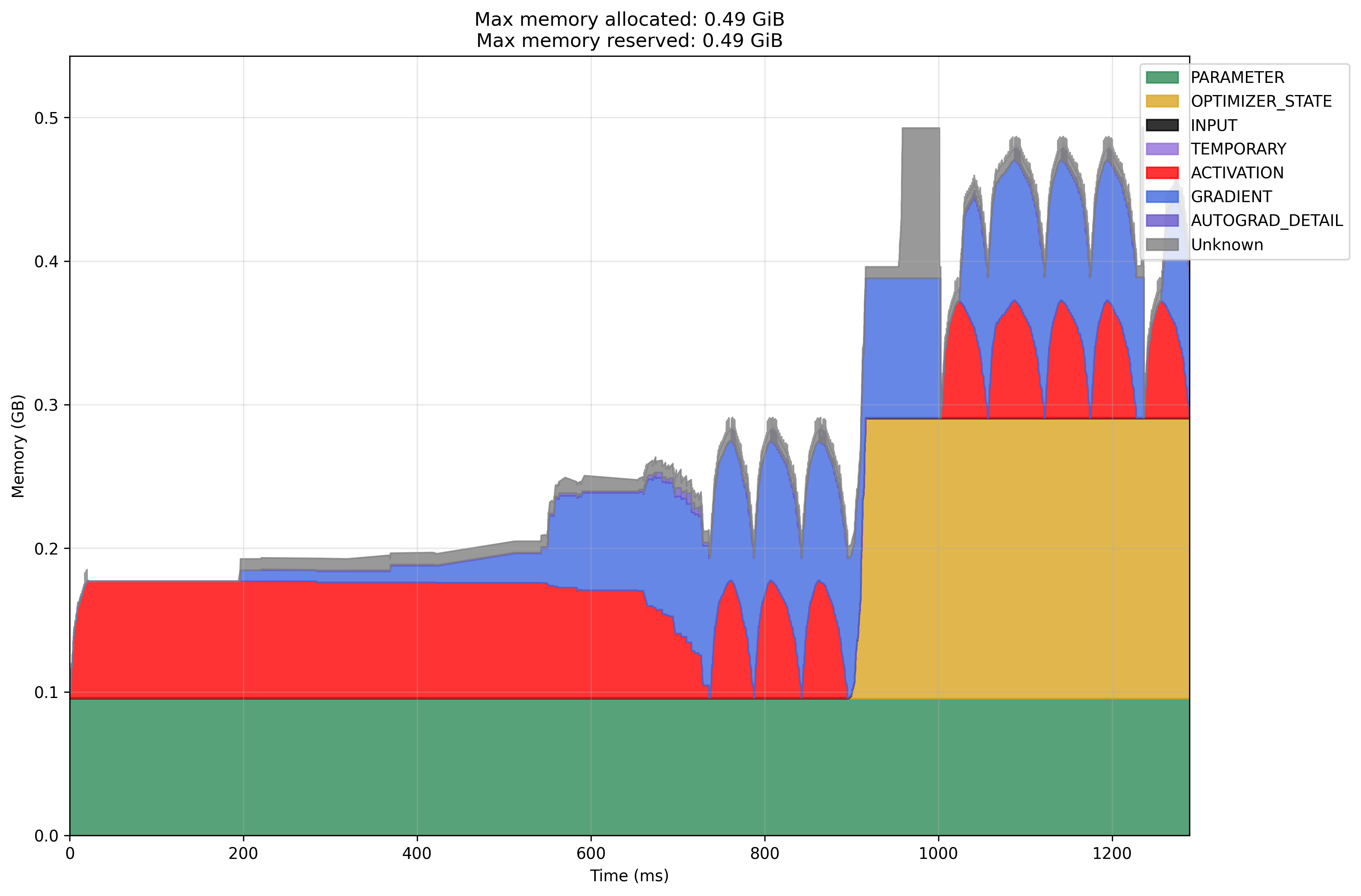
optimizer-memory-profiles
I ran the template PyTorch Memory Profile code in several settings.
| Execution Environment | Hardware Type | Optimizer | Gradient Accumulation | Memory Profile |
|---|---|---|---|---|
| Local | CPU | SGD | No | View |
| Remote | CPU | SGD | No | View |
| Remote | GPU | SGD | No | View |
| Remote | GPU | SGD + Momentum | No | View |
| Remote | GPU | Adam | No | View |
| Remote | GPU | Adam | Yes | View |
Running the profiling
modal run profiling.py
Notes
These are some observations
- I do not know why memory is not correctly attributed to activation in the Local CPU setting
- I probably want some explanation on why the first iteration on the GPU is slow
- I want to know what is the memory allocated to ‘Unknown’ is used for in Adam optimizer
- It seems that we should budget memory for 5 times the number of parameters
- There is also a view (source) on the specific memory usage
Memory Profiling Results
Local CPU SGD
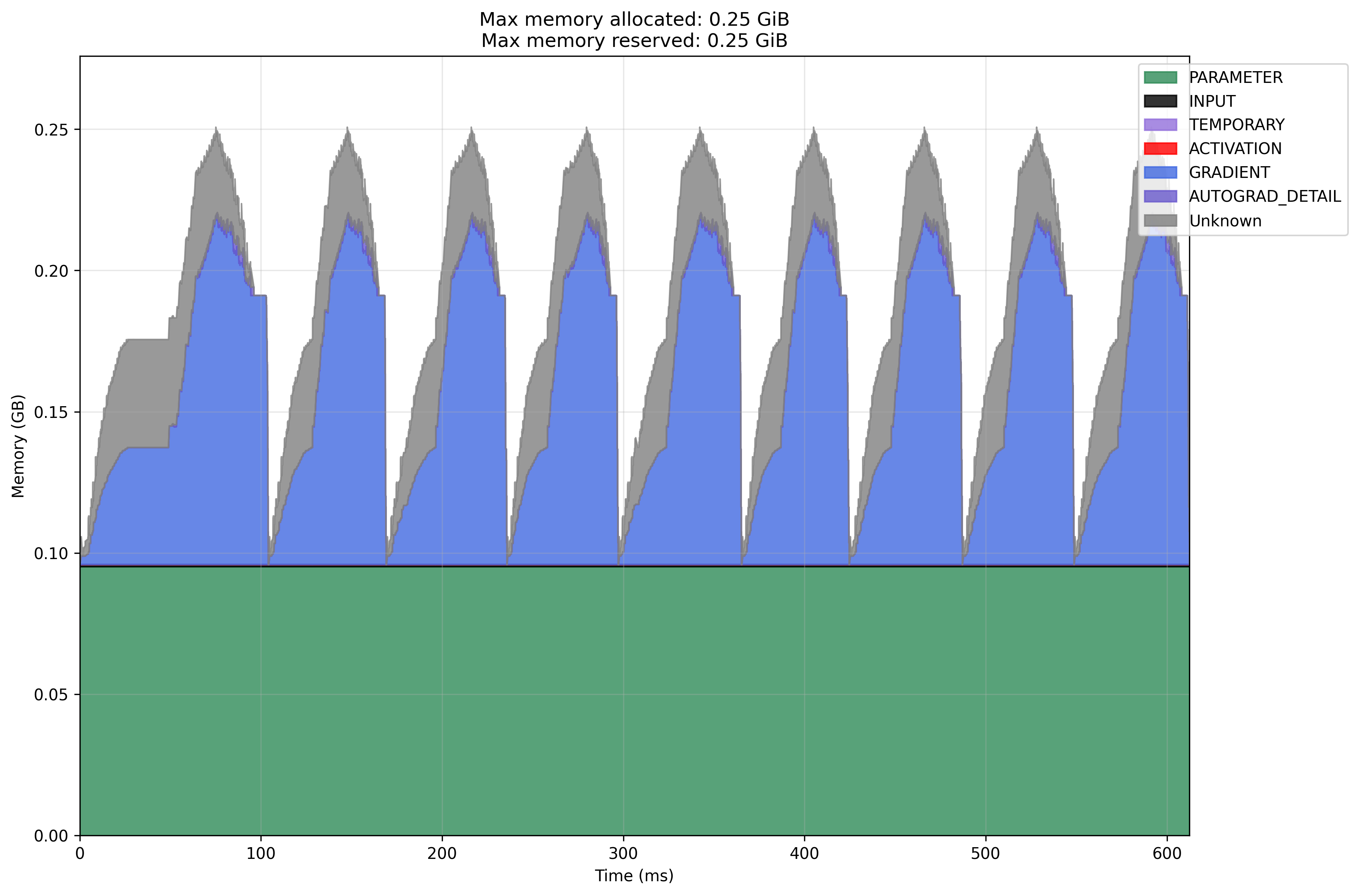
Modal CPU SGD
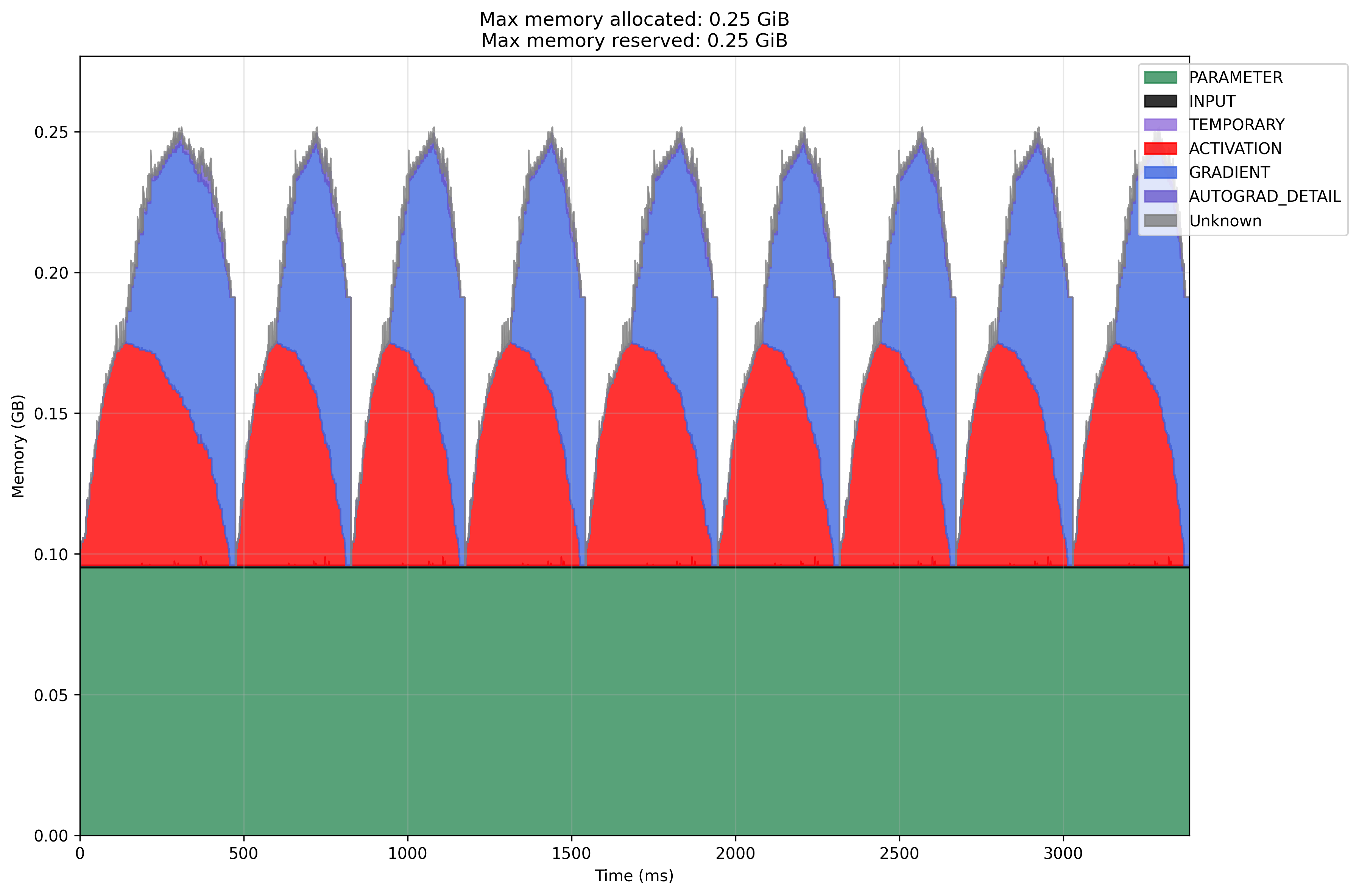
Modal GPU SGD
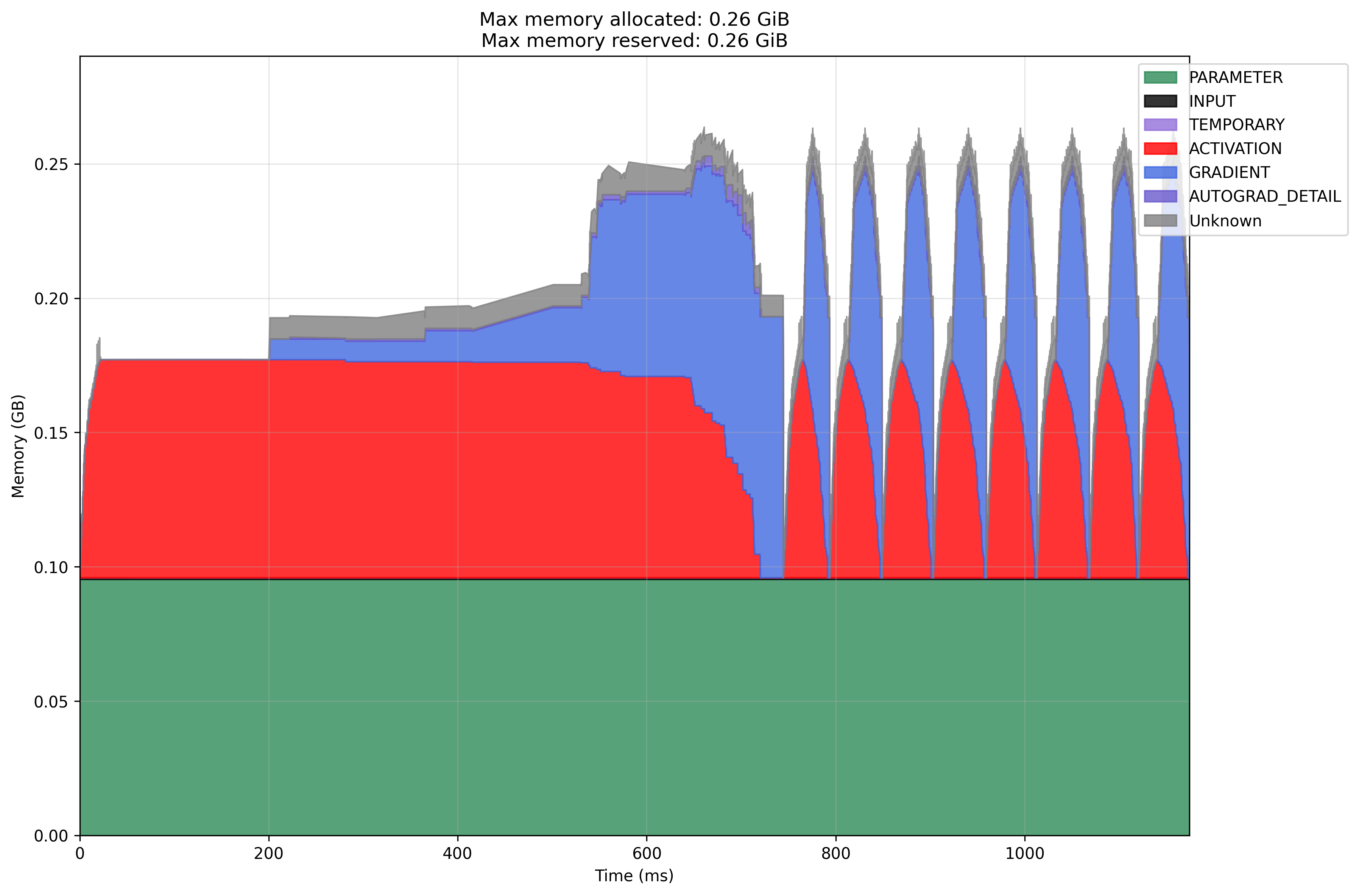
Modal GPU SGD with Momentum
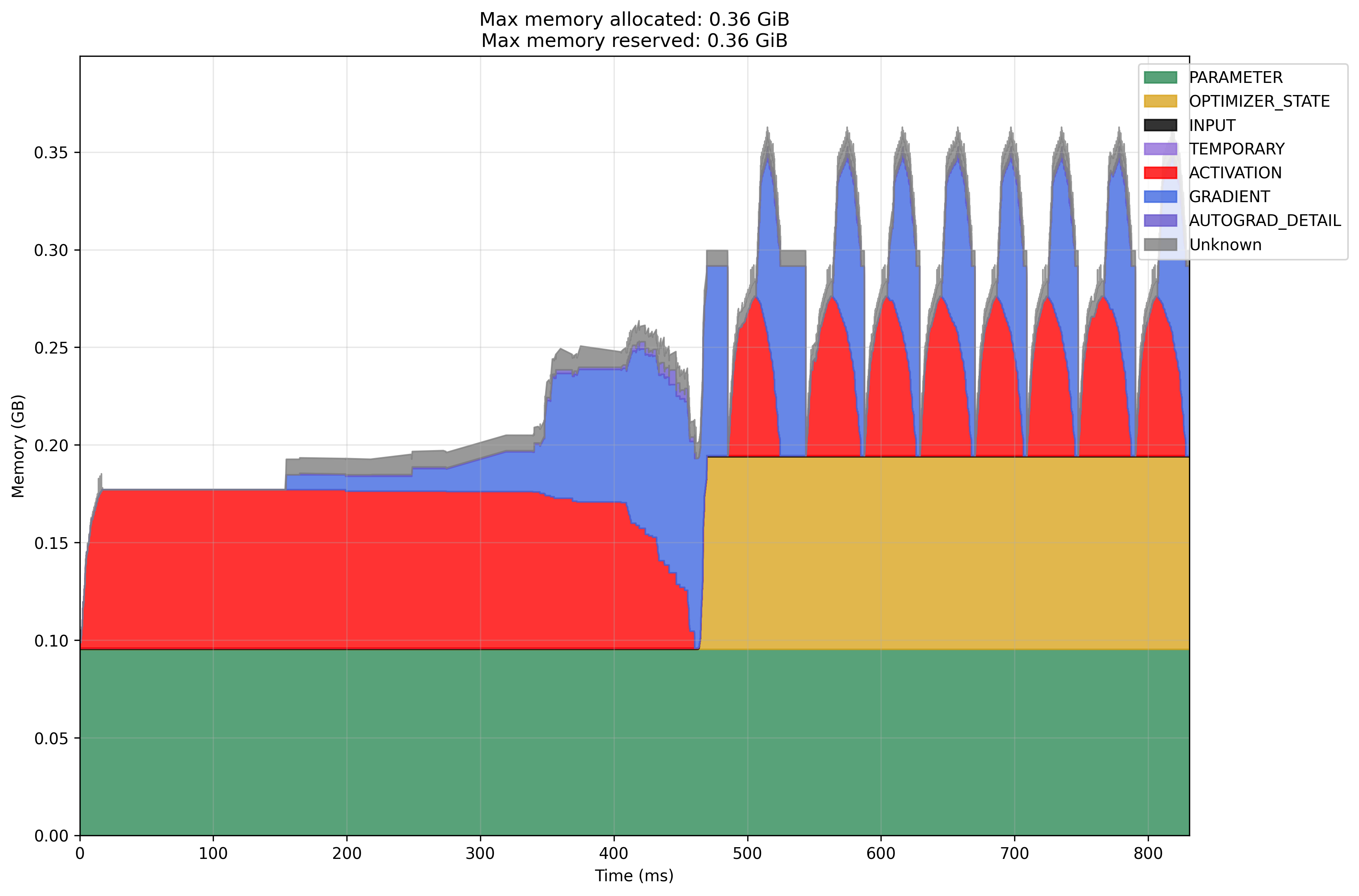
Modal GPU Adam
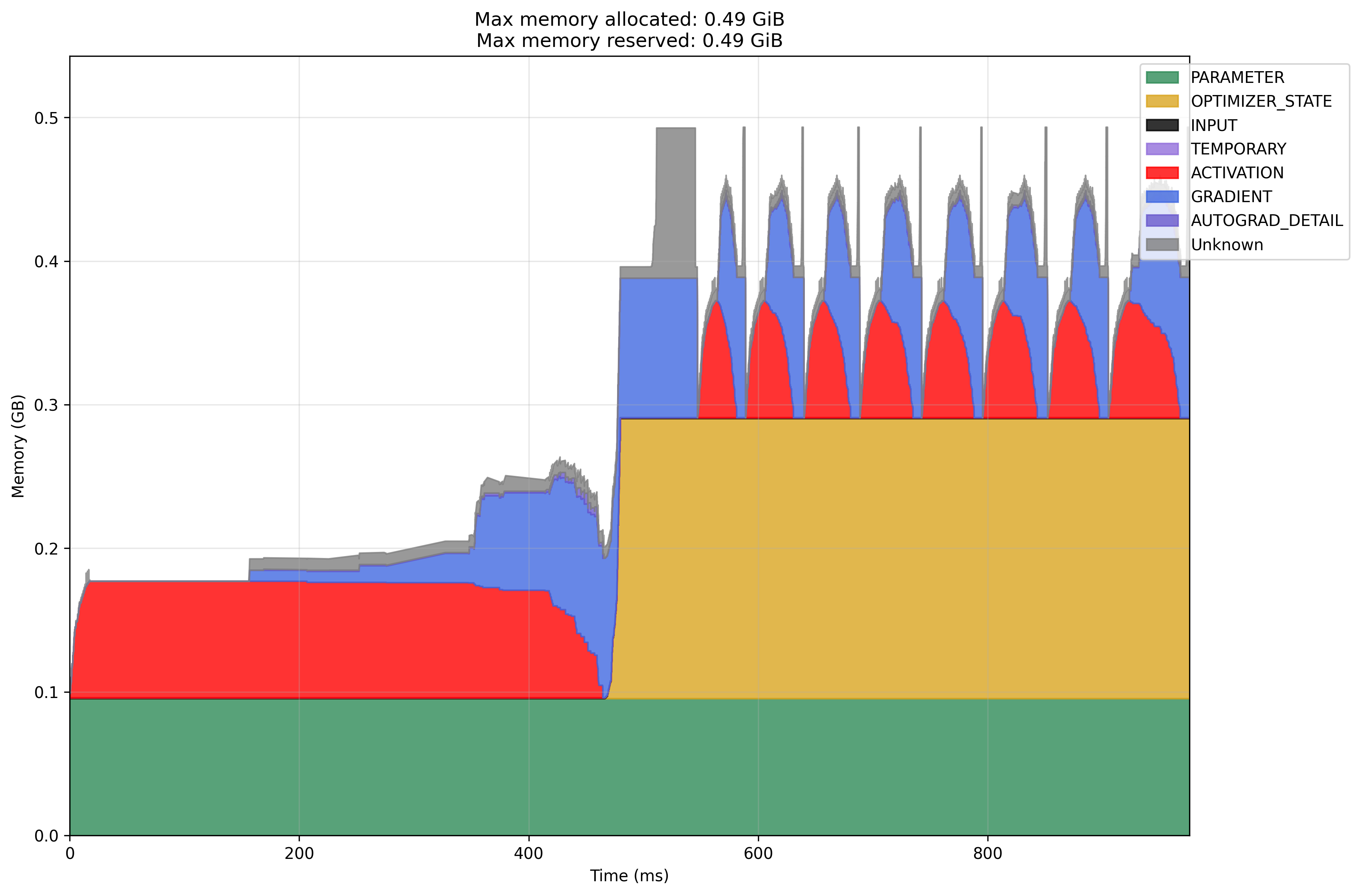
Modal GPU Adam with Gradient Accumulation